Exploring automatic Buffer Management with io_uring
07·06·2026
In the last year or so I’ve been working on UringMachine, a Ruby gem for doing I/O with io_uring, and I’ve been reporting on my progress on my website, as part of my grant work for the Ruby Association.
A Quick Recap
Here’s a quick recap of what UringMachine does: UringMachine provides a low-level API for performing I/O operations using io_uring, which is an interface for performing I/O operations asynchronously on recent Linux kernels.
UringMachine also provides a Fiber Scheduler implementation that allows it to integrate nicely with the rest of the Ruby ecosystem and be used in any Ruby application that supports fiber concurrency.
In my work on this project I’ve been looking to find just the right level of abstraction that on the one hand allows harnessing the full power of io_uring to bring high-performance I/O to Ruby, and on the other hand provide a convenient and practical Ruby API, and good integration with the entire Ruby ecosystem.
Here are some of the things I’ve been working on since starting the grant work:
- A full-featured
FiberSchedulerinterface implementation. - Some minor contributions to the
FiberSchedulerintegration code in the Ruby runtime. - Comprehensive tests.
- Support for
IO::Bufferin the different I/O methods. - Support for vectorized
writev/sendv. - Comprehensive metrics.
- Support for SQPOLL mode.
- Support for Sidecar mode.
- Lots of benchmarking.
Automatic Buffer Management
During the last few months I’ve been working on implementing automatic buffer manangement for UringMachine. As is my custom, I’ve been thinking about the design for this feature and trying different ideas. Following the last Christmas vacation I figured the design is solid enough for me to start writing some code. But let me back up and explain what I’m trying to achieve here.
One of the more recent features of the io_uring interface is a facility for setting up buffer rings. The idea is that the application provides buffers to the kernel, which can then use those buffers for reading or receiving data repeatedly from a given file or socket, letting the application know with each CQE which buffer was used and how much data was put into it.
The application initiates multishot read/recv operations on each connection, and the kernel has at its disposition a pool of application-provided buffers that it can use whenever a chunk of data is read / received. So the kernel consumes those buffers as needed, and fills them with chunks of data as they are read from sockets. Those chunks of data will be processed by the application at some later time when it’s ready to process CQEs. Eventually, after processing the data, the application will add the consumed buffers back to the buffer ring, making them available to the kernel again.
Multiple buffer rings may be registered by the application, each with a set
maxmimum number of buffers and with a buffer group id (bgid). The buffers
added to a buffer ring may be of any size. Each buffer in a buffer ring also has
an id (bid). So buffers are identified by the tuple [bgid, bid]. When
submitting a multishot read/recv operation, we indicate the buffer group id
(bgid), letting the kernel know which buffer ring to use. The kernel then
generates CQEs (completion queue entries) which contain the id of the buffer
that contains the data (bid). Crucially, a single buffer ring may be used in
multiple concurrent multishot read/recv operations on different file
descriptors.
In addition,on recent kernels io_uring is capable of partially consuming buffers, which prevents wasting of buffer space. When a buffer ring is set up for partial buffer consumption, each CQE relating to a multishot read/recv operation will also have a flag letting the application know whether the buffer will be further used beyond the amount of data readily available. Each read/recv completion with the same buffer ID will continue where the previous one left off. This means that buffer space is used fully, but the “downside” of this is that the application is required to keep track of a “cursor” for each buffer.
So I wanted to design a sub-system that manages buffers automatically: registering buffer groups, allocating and adding buffers to the individual buffer rings, and keeping track of the usage of each buffer. But I also wanted to come up with a good way to use these buffers from the point of view of the application.
How Applications Use Buffers
How do we normally use I/O buffers in Ruby applications? The stock IO class
conveniently includes buffering functionality for both reading and writing from
a file/socket. These makes it possible to implement APIs like IO#gets, which
perform buffered reads and look for line delimiters in the read buffers.
Depending on the protocol, we might need to read data line by line, or a single
byte, or maybe a string with an arbitrary length, or a combination of those. So,
an application that wants to parse, say, an HTTP/1.1 request, will need first to
read the request headers, each of which is terminated by a \r\n separator, and
then read the request body, which has an arbitrary length, according to the
given headers. This makes it necessary to read data into a buffer, which might
need to be resized and/or truncated as more data is read.
So, we might imagine an abstraction that lets us read from an some source that is a stream of bytes. We might want to read a line:
stream.read_line
Or we might want to read 42 bytes exactly:
stream.read(42)
In order to that, we need to buffer data we read from the stream, since we
either need to read until encountering a delimiter, or we do need to read an
exact amount, and may get shorter reads, and we want the buffering to work
automatically, just as it is done in the normal IO class, where you don’t need
to think about, you just call IO#read.
So here are our goals:
- Provide a simple API that works for both binary and line-based protocols.
- Use io_uring’s provided buffers feature.
- Reuse buffers.
- Adapt total buffer space to read pressure.
- Minimize allocation buffers.
- Minimize copying of read data.
Now let’s see how UringMachine achieves these goals.
Automatically supplying buffers for read operations
As discussed above, io_uring organizes provided buffers into buffer groups (or buffer rings). The same buffer group can be used for any number of concurrent multishot reads, meaning io_uring can use the same buffer space for data coming from any number of sockets that are currently being serviced by the application. The application just needs to track the buffer usage along with the kernel, in order to know where the data resides for each of those sockets.
So we start by setting up a buffer ring with 1024 entries, which will be used for any multishot read/recv. We populate the buffer ring/group with 16 buffers, each 16KB in size, for a total of 256KB. We aim to maintain a level of available buffer space of between 128KB at 256KB at any given time.
As multishot reads will be performed, io_uring will consume data incrementally from these buffers, so for each buffer we also have a cursor which tracks how much of it is already consumed.With each CQE we receive from io_uring, the kernel tells us which buffer was used, and how much data was read into it, which we can then use to increment the cursor.
As multishot CQEs arrive, we can also track the total amount of buffer space available to the kernel. We setup an auto-refill mechanism that tracks the total buffer space, and in case it falls beneath 128KB, adds more buffers to the buffer group in order to go back to having at least 256KB available to the kernel.
If there’s lots of data arriving at the same time, we may get a situation where
buffer space is exhausted, which the kernel will let us know about by stopping
the multishot read and returning a ENOBUFS error code (which also means we
need to restart the multishot read). In that case, the auto-refill mechanism
will double the total buffer space level, as well as the minimum threshold, so
available buffer space will be maintained at 256KB to 512KB at all times.
Minimizing copying
While one of our goals is to refrain from copying data as much as possible, we have the problem that since the same buffers may be used for multiple concurrent multishot reads, we have no guarantee that the read data for a specific socket will be contiguous in the buffer. In other words, we need to be able to deal with a segmented buffer, which consists of one or more segments. Each of those segments is basically a reference to a chunk from a specific buffer. We can then arrange those segments in a linked list, and thus be able to reconstitute the entire received message:
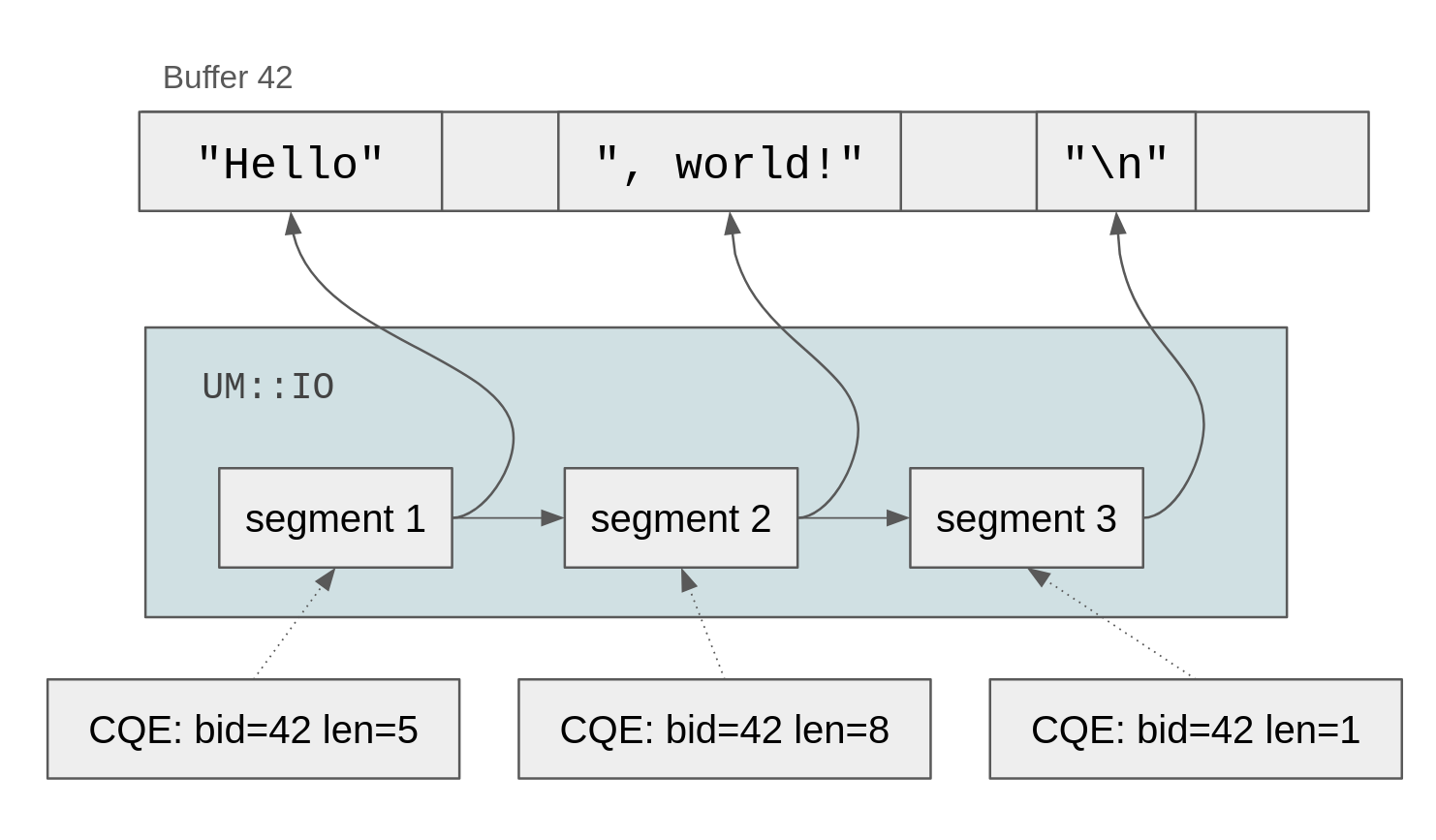
This means that we only need to copy data once, when we convert the read data
into a Ruby string. In the example above, when #read_line is called, we search
for the first occurrence of \n, starting from the first segment. Once the
delimiter is found (in the third segment), we can allocate a Ruby string with
the required capacity, and copy data from each of those segments into the string.
This way we only copy the data once from those buffers. Once an entire buffer has been consumed by the kernel, and all of the generated segments referring to that buffer have been consumed by the application, the buffer can be safely recycled and eventually provided again to the kernel.
Minimizing allocations
So we have buffers that provide a general space for the kernel to read into, we
provide those buffers to the kernel, they’re consumed by it, we then read data
from those buffers, and once we’re done with a buffer, we want to be able to
reuse it. We also have those little segment structs that need to be allocated
and managed. How do we do that? When a segment is consumed, we put it on a free
list, such that the next time we need a segment struct, we just grab one from
the free list. That way, we minimize the number of allocations. Actually
UringMachine also the same with the um_op struct that holds metadata about an
I/O operation, and various other struct types.
And of course, since we can use the same buffers for servicing any number of ongoing multishot read operations, that means that we no longer need to allocate (and later deallocate) buffer space for each file descriptor we wish to read from.
Putting it all together
What I like about this design is that it makes use of an avanced io_uring
feature, and does so in a way that is completely seamless for the developer, who
benefits from a simple and practical API. In UringMachine, I chose to provide
this API as part of the UringMachine::IO class, which provides a small set of
methods for buffered I/O, as well as some other methods for writing/sending data
and interrogating buffer state:
# instantiate an IO
io = UM::IO.new(machine, fd)
# or:
io = machine.io(fd)
io.read(count) #=> read count bytes from the stream
io.read_line(maxlen) #=> read until \n is encountered
io.read_to_delim(delim, maxlen) # read until delimited is encountered
io.read_each { |segment| } # iterate over segments
io.skip(count) #=> skip count bytes in the buffer
io.write(*strings) #=> write the given strings
io.clear #=> clear the buffer
Here’s how a rudimentary HTTP/1.1 parser could be built on top of it:
# HTTP protocol extensions for UM::IO
class UM::IO
def http_read_request_headers
line = read_line(MAX_REQUEST_LINE_LEN)
headers = parse_request_line(line)
return nil if !headers
loop do
line = read_line(MAX_HEADER_LINE_LEN)
k, v = parse_header_line(line)
break if !k
headers[k] = m[v]
end
headers
end
def http_read_body(headers)
content_length = headers['content-length']
if content_length
content_length = content_length.to_i
return nil if content_length == 0
chunk = read(content_length)
return chunk
end
nil
end
...
end
We can then easily build a web server on top of those HTTP protocol primitives:
def handle_http_client(fd)
io = @machine.io(fd)
while true
headers = @io.http_read_request_headers
break if !headers
body = @io.http_read_body(headers)
handle_request(io, headers, body)
end
ensure
@machine.close(fd)
end
What I think is great about this design, is that one one hand it hides all of the buffering that UringMachine is doing, and on the other it lets you keep writing code in a sequential style, where you stay in control, and refrain from using callbacks.
Another thing that I like about this design, is that the level of abstraction
matches the design of the protocol. In HTTP/1, the sequence of how an HTTP
request looks is always the same: headers (including the request line), then
body. So it’s fitting that we have two methods that correspond to the message
structure: http_read_request_headers, then http_read_body.
Implementing other protocols
So, just like HTTP, we can also implement other protocols on top of the UM::IO
class. In fact, UringMachine includes an implementation of the RESP
protocol used by
Redis servers.
Since the RESP protocol is built around exchanging simple, nestable data types including arrays and hashes, we can design the protocol around this:
io.resp_read #=> reads a String, Integer, Array, Hash etc
io.resp_write(obj) # sends an object
Such that in order to talk to a Redis server, here’s what we need to do:
fd = machine.tcp_connect('127.0.0.1', 6379)
io = machine.io(fd)
# client handshake
io.write("HELLO 3\r\n")
res = io.resp_read
# issue command
io.resp_write(['get', 'foo'])
value = io.resp_read
What’s next for UringMachine
All in all, I’m really happy about UringMachine. The design feels solid, the performance is good, and the included fiber scheduler implementation makes it possible to integrate it with the entire Ruby ecosystem.
So, what’s next for UringMachine? Here are some of the things I intend to continue working on:
- Support for IPv6 addresses.
- Support for
sendto/recvfrom. - More protocol implementations on top of
UM::IO: HTTP/1, HTTP/2, PostgreSQL wire protocol. - Allow usage with projects such as Rails (basically it works!), Hanami and Sidekiq.
In the coming few weeks I’ll start writing about the project I’m currently focusing on, based on my work on UringMachine. Take care!